
Stosując wybrany algorytm, warto znać jego ograniczenia. W tym wpisie skupiam się na tych, które dotyczą algorytmu k-średnich.
Z tego artykułu dowiesz się: 1. Jakie są główne założenia algorytmu k-średnich? 2. O jakich ograniczeniach należy pamiętać stosując k-średnich? 3. Jak przeciwdziałać wspomnianym ograniczeniom?
Ostanie dwa wpisy na blogu skupiały się na teorii i praktycznym użyciu algorytmu k-średnich. Dziś chciałbym się bliżej przyjrzeć pewnym jego ograniczeniom tego algorytmu, z których być może nie każdy zdaje sobie sprawę. Zaczynamy! 😉
- Algorytm wymaga od użytkownika ustalenia liczby grup.
Zanim uruchomisz algorytm, należy a priori podać liczbę grup, które mają zostać wyznaczone. Bez uprzedniego wizualizowania zbioru lub wykonania dodatkowych analiz jest to dosyć trudne.Rozwiązania:
- Należy wykonać wizualizację obserwacji w przestrzeni 2 lub 3-wymiarowej. Rzut oka na obserwacje może dać pewną intuicję na temat optymalnej liczby grup.
- Użycie wykresu łokcia – obrazuje on na jednej osi liczbę grup, a na drugiej sumę kwadratów odległości poszczególnych obserwacji od centroidów. Wybieramy liczbę grup, przy której jest widoczne znaczne załamanie spadku sumy kwadratów – dodanie kolejnej grupy nie przynosi już aż tak dużych korzyści.
- Użycie wykresu ze średnią wartością wskaźnika sylwetkowego (ang. silhouette coefficient) – podobnie jak w przypadku wykresu łokcia oś x, to liczba grup. Oś y to średnia miara sylwetki (profilu) wszystkich obserwacji zbioru. Wskaźnik sylwetki mówi o tym, jak poszczególna obserwacja:
- jest podobna do pozostałych obserwacji w grupie,
- jest różna od obserwacji w pozostałych grupach.
Wybrać należy liczbę grup, dla której średnia wartość sylwetki jest największa.
- Wrażliwość na dobór punktów startowych.
W pierwszej iteracji swojego działania algorytm losowo dobiera punkty startowe. To jak dobre wyniki uzyska, zależy zatem w pewnym stopniu od czynnika losowego.Rozwiązanie:
- Należy wykonać kilka wykonań algorytmu z losowo wybieranymi punktami startowymi. Niektóre biblioteki domyślnie uruchamiają grupowanie metodą k-średnich n-razy (w sklearn jest to 10, lecz wartość parametru można zmienić). Finalnym rezultatem jest grupowanie o najlepszej wartości zadanej miary jakości (np. wskaźnika sylwetkowego).
- Wrażliwość na wpływ obserwacji odstających i szum.
Podobnie jak wartość średnia, tak i algorytm k-średnich jest wrażliwy na wpływ obserwacji odstających. Przyczyna jest błaha: do wyznaczenia przeciętnej obserwacji używana jest wartość średnia współrzędnych wszystkich obserwacji danej grupy. Tak więc, średnia współrzędna nie zawsze jest optymalną wartością do wyznaczenia położenia grupy.Rozwiązanie:
- Wstępne przygotowanie danych i usunięcie wartości odstających.
- Użycie alternatywnego algorytmu o podobnym działaniu do k-średnich, lecz niewrażliwego na obserwacje odstające, np. k-median, k-medoidów (PAM).
- Każda z powstałych grup będzie posiadać przybliżoną liczbę obserwacji.
Powyższe ograniczenie wynika ze sposobu, w jaki działa algorytm i z bazowych założeń.Rozwiązanie:
- Temu problemowi ciężko w prosty sposób przeciwdziałać w przypadku algorytmów iteracyjno-optymalizacyjnych. Najprostszym sposobem wydaje się zmiana algorytmu na hierarchiczny lub algorytm grupowania gęstościowego.
- Zakłada, że grupy są sferyczne.
Problem ten jest znakomicie widoczny w przykładzie ze wpisu dotyczącego praktycznego użycia algorytmu k-średnich.Rozwiązanie:
- Podobnie jak w przypadku problemu numer 5, tak i tutaj nie mamy prostej odpowiedzi. Najprostszym sposobem wydaje się zmiana algorytmu na hierarchiczny lub algorytm grupowania gęstościowego.
- Algorytm wspiera jedynie zmienne numeryczne.
By liczyć średnie ze współrzędnych obserwacji, konieczne jest używanie zmiennych numerycznych. Co więcej, zmiana kodowania zmiennych dyskretnych może wprowadzać szum.Rozwiązanie:
- W przypadku, gdy analizowany zbiór zawiera jedynie zmienne dyskretne, to rozwiązaniem może być zmiana algorytmu na algorytm k-modes. Służy on do grupowania obserwacji opisanych za pomocą zmiennych kategorycznych. Bazuje na częstościach występowania kategorii.
- W przypadku, gdy analizowany zbiór zawiera zarówno zmienne dyskretne, jak i zmienne ciągłe, to potencjalnym rozwiązaniem może być zmiana algorytmu na algorytm k-prototypes. Jest on kombinacją algorytmów: k-modes i k-średnich.
- Jako „półśrodek” może być wykonana zmiana kodowania na one-hot encoding, które z matematycznego punktu widzenia jest „mniejszym złem” niż label encoding.
- Założenie co do równej wariancji zmiennych.
Zgodnie z założeniami algorytmu wszystkie zmienne powinny mieć tę samą wariancję.Rozwiązania (dla każdej zmiennej numerycznej należy wykonać jedną z operacji):
- Standaryzacja:
- Skalowanie:
- Standaryzacja:
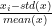

Sprawdź również wpis dotyczący metod optymalizacji parametrów modelu
Podsumowanie
W kolejnych wpisach skupię się na algorytmach iteracyjno-optymalizacyjnych, które starają się niwelować niektóre z wymienionych dziś ograniczeń. Będzie też nieco więcej na temat zmiennych dyskretnych w kontekście problemu grupowania.
Jeśli chciałbyś się odnieść do moich słów lub zadać pytanie, to zapraszam do dyskusji w komentarzach pod wpisem. 🙂 A Ty jak sobie radzisz z ograniczeniami algorytmu k-średnich?