
Bardzo popularny temat w środowisku data science: wyznaczanie rekomendacji. Jeśli mowa o rekomendacjach to wybór zbioru danych nie może być inny niż zbiór filmów i ich atrybutów. Klasyka Data Miningu 🙂 Jeśli chcesz zobaczyć proces implementacji zbiorów rozmytych w silniku rekomendacji, to zapraszam do zapoznania się z treścią wpisu.
- Wstęp.
- Wybór metody filtrowania.
- Przygotowanie modelu danych.
- Uzupełnienie modelu danymi.
- Obróbka i normalizacja danych.
- Przygotowanie algorytmów.
- Wyznaczenie stopnia podobieństwa pomiędzy filmami.
- Wyznaczenie współczynnika wsparcia rekomendacji.
- Przedstawienie wyników oraz wniosków.
Wstęp
Silnik rekomendacji jest to system informatyczny, pozwalającą przewidzieć na podstawie wybranych koncepcji grupowania, w jakim stopniu dany produkt spełni oczekiwania użytkownika. Systemy rekomendacyjne można podzielić na trzy podstawowe grupy względem koncepcji grupowania:
- Systemy bazujące na powiązaniach cech produktów bądź usług (ang. Content Base Filtering);
- Systemy bazujące na powiązaniach pomiędzy użytkownikami (ang. Collaborative Filtering);
- Systemy hybrydowe wykorzystujące obydwie koncepcje.
Wszystkie z wyżej wymienionych metod mają swoje wady i zalety. W przypadku użycia pierwszej metody (Content Base Filtering) algorytm opierałby swoje działanie jedynie na atrybutach/cechach charakterystycznych danego filmu. Na poziom zadowolenia użytkownika składa się znacznie więcej czynników, dlatego dwa filmy tego samego gatunku pomimo tych samych atrybutów charakterystycznych (rok produkcji, popularność, reżyser) mogą mieć skrajnie różne oceny wśród użytkowników. Dzieje się tak, ponieważ ocena będąca odzwierciedleniem naszego zadowolenia jest wartością subiektywną, której nie można sprowadzić do kilku atrybutów.
Wady:
- ograniczanie się jedynie do „suchych” atrybutów;
- brak czynnika ludzkiego.
Zalety:
- szybkość;
- brak ograniczenia w postaci „zimnego startu”.
Drugie podejście do grupowania filmów (Collaborative Filtering) opiera się na idei społeczności. Algorytm znajduje podobieństwa między użytkownikami i na podstawie tej wartości rekomenduje filmy obejrzane przez użytkowników o podobnym guście filmowym. W podejściu tym rekomendacje ograniczają się jednak do filmów już ocenionych przez użytkowników. Dużym problemem jest charakterystyka branży filmowej. Użytkownicy lubią odkrywać nowe filmy. W przypadku, gdy dany film nie został oceniony przez użytkowników (bądź użytkowników podobnych „profilem” do nas), to zostaje on pominięty przy rekomendacjach. Drugim problemem jest tzw. zimny start. W przypadku braku informacji o ocenach użytkowników rekomendacje nie mogą zostać wyznaczone.
Wady:
- „zimny start”,
- szybkość, a w zasadzie jej brak.
Zalety:
- czynnik ludzki.
Wybór metody filtrowania
Po analizie wyżej wymienionych wad i zalet Content Base Filtering oraz Collaborative Filtering, oraz charakterystyki branży filmowej, podjąłem decyzję o implementacji pierwszego podejścia. W przypadku wyboru drugiej metody, dane scoringowe musiałyby być odświeżane za każdym razem, gdy ktoś oceni film. Implementacja takiego podejścia wymagałaby dużo większych zasobów w postaci mocy obliczeniowej i obejścia problemu dużej złożoności obliczeniowej, „na skróty”, np. odświeżania danych co interwał 60 minutowy. W przypadku filtrowanie opartego o atrybuty filmów, również mamy do czynienia z dużą złożonością obliczeniową procesu wyznaczania rekomendacji, natomiast powiązania pomiędzy filmami nie muszą być odświeżane tak często. Wystarcza cotygodniowe, nocne odświeżenie stopnia przynależności filmów i ich atrybutów. Do tego można dodać codzienne, nocne odświeżanie preferencji użytkowników.
Moja decyzja nie oznacza jednak że wspomniany „czynnik ludzki” został całkowicie wyeliminowany. Podczas implementacji opierałem się o atrybuty takie jak: Ocena, oraz Popularność danego filmu. Obie wartości pozyskałem z trzech różnych źródeł: filmweb, IMDB, oraz theMovieDB.org.
Silnik bazuje na algorytmie rekomendacji opracowanym z wykorzystaniem mechanizmów zaczerpniętych z teorii zbiorów rozmytych. Jako że filmy to jedna z moich pasji, to algorytm został dopasowany do charakterystyki branży filmowej w oparciu o wiedzę mojej skromnej osoby 🙂
Wszystkie filmy są oceniane w skali od 1 do 5. Pierwszym ważnym założenie jest to, że filmem lubianym przez daną osobę jest film oceniany na co najmniej 4.
W projekcie korzystałem z następujących technologii i języków programowania:
- MySQL
- Python
Tu zatrzymam się na chwilę, bo pewnie zastanawiasz się czemu wybrałem właśnie taki zestaw. Otóż Data Science to sposób myślenia i rozwiązywania problemów, a nie narzędzia, dlatego podjąłem decyzję, że każdy ze swoich projektów przedstawianych na blogu będę opierać o inną technologię. Dziś swoje 5 minut ma Open Source.
Przygotowanie modelu danych
Zacznę od początku, czyli od danych i sposobu ich przechowywania. Model danych został utworzony przy użyciu relacyjnej bazy danych rozwijanej przez firmę Oracle – MySQL. Czemu MySQL? ona w pełni darmowa, obsługuje widoki, wyzwalacze i funkcje, które były niezbędne do implementacja logiki rozmytej.
W systemie rekomendacyjnym szybkość jego działania oraz dokładność prognozowania w dużej mierze opiera się na poprawnie zbudowanej strukturze bazy danych. Na potrzeby niniejszego systemu rekomendacji filmów została zaprojektowana baza danych składająca się z następujących tabel:
- Filmy – tabela zawierająca podstawowe dane dotyczące filmów, m.in. tytuł polski, tytuł oryginalny, czas trwania, rok produkcji, opis filmu, średnia ocena, popularność;
- Uzytkownicy – tabela zawierająca dane użytkowników niezbędne do logowania. Tabela jest połączona z tabelą Filmy tabelą intersekcyjną: FK_Uzytkownicy_Filmy;
- Rezyserzy – tabela, w której zawarte są nazwy reżysera;
- Keywords – tabela ze słowami kluczowymi opisującymi film. Połączona połączeniem wiele do wielu z tabelą Filmy za pomocą tabeli intersekcyjnej FK_Keywords_Filmy;
- Aktorzy – tabela, w której zawarte są nazwy aktorów. Tabela jest połączona z tabelą Filmy połączeniem wiele do wielu poprzez tabelę intersekcyjną FK_Aktorzy_Filmy;
- Gatunki – tabela z nazwami gatunków. Każdy film może mieć przypisany jeden lub więcej gatunków. Tabela połączona z tabelą Filmy poprzez tabele intersekcyjną FK_Gatunki_Filmy;
- Panstwa – tabela z nazwami krajów produkcji filmów. Każdy film może mieć przypisane jedno lub wiele państw. Tabela połączona z tabelą Filmy połączeniem wiele do wielu za pomocą tabeli intersekcyjnej FK_Panstwa_Filmy;
- Jezyki – tabela z językami filmów. Każdy film może mieć przypisany jeden lub wiele języków. Tabela połączona tabelą intersekcyjną FK_Jezyki_Filmy z tabelą Filmy;
- FK_Filmy_Filmy – tabela iloczynu kartezjańskiego wszystkich filmów. Zawiera informacje dotyczące stopnia podobieństwa pomiędzy filmami.
Model fizyczny bazy danych wygląda następująco:

Uzupełnienie modelu danymi
Zdecydowanie najbardziej czasochłonny etap. Już po utworzeniu bazy danych oraz umieszczeniu jej na serwerze kolejnym krokiem było uzupełnienie bazy o dane filmów, oraz uzupełnienie ewentualnych braków. Dane o filmach zostały pobrane z kilku serwisów oferujących bezpłatne API dla programistów. Były to m.in.:
Dane z powyższych serwisów zostały pobrane i zapisane do bazy danych z użyciem skryptów napisanych w języku Python. W pierwszym kroku pobrałem dane o filmach z serwisu http://themoviedb.org. Plik theMovieDB.py zawiera wszystkie metody potrzebne do pobrania informacji z serwisu. Główną funkcją w skrypcie jest FindMovie(title, date), która wyszukuje dane o filmach bazując na tytule i roku produkcji. Pobieranie danych odbywa się z użyciem pakietu pythonrequests dostępnego w standardowej bibliotece Python – urllib2. Parametrem głównego polecenia jest klucz api programisty oraz wyszukiwana fraza. Funkcja domyślnie zwraca dane z wyszukiwania w formacie JSON. W przypadku wyszukiwania z użyciem frazy skrypt spośród pobranych danych zwracał identyfikator filmu, który w najlepszym stopniu spełniał kryteria wyszukiwania. Identyfikator mógł zostać użyty do wyszukiwania szczegółowych informacji o filmie.
Oczywiście zdarzało się, że pobrane dane były niekompletne, dlatego pierwsze braki starałem się uzupełniać już przy pobieraniu podstawowych informacji o filmie. Jak to robiłem? Otóż skrypt w przypadku braków danych wywoływał kolejne metody mające na celu owe braki uzupełnić korzystając z innych źródeł. Używałem do tego kolejnej metody: GetAllData(movieId). Metoda na wejściu przyjmowała parametr będący poprawnym identyfikatorem filmu używanym w serwisie http://themoviedb.org. Zwracała dane w formacie JSON.
Dodatkowo w obrębie skryptu theMovieDB.py istnieją inne metody wykorzystujące identyfikator filmu:
- GetAllData_cast(movieId) – metoda pobierająca dane o obsadzi filmu: aktorach, obsłudze;
- GetKeywords(movieId) – metoda pobierająca słowa kluczowe opisujące film.
Wszystkie dane zwracane przez powyższe metody były parsowane przez następujące metody (parametr wejściowy data to dane wyjściowe funkcji GetAllData, bądź GetAllData_cast) m.in.:
- GetVoteAverage(data) – metoda zwracająca średnią ocenę filmu;
- GetReleaseDate(data) – metoda zwracająca datę produkcji filmu;
- GetGenres(data) – metoda zwracająca listę gatunków danego filmu;
- GetRuntime(data) – metoda zwracająca czas trwania filmu;
- GetPopularity(data) – metoda zwracająca współczynnik popularności filmu;
- GetDescription(data) – metoda zwracająca opis filmu;
- GetProductionCountries(data) – metoda zwracająca listę krajów produkcji filmu;
- GetCast(data) – metoda zwracająca dane o obsadzie filmu;
- GetDirector(data) – metoda zwracająca dane reżysera filmu;
- GetIMDBId(data) – metoda zwracająca identyfikator filmu z największej na świcie bazy filmów – IMDB.
W skrypcie theMovieDB.py metody pobierające i parsujące dane zostały rozdzielone ze względu na dużą złożoność obliczeniową całego procesu. Ze względu na ograniczenia nakładane przez stronę http://themoviedb.org polecenia mogły być wysyłane z określoną częstotliwością. Dane pobrane za pomocą powyższego skryptu zostały zapisane do bazy danych za pomocą skryptu Movies.py. Skrypt w pętli pobierał dane kolejnych filmów i zapisywał je do bazy danych.
Dodatkowo część niezbędnych danych została pobrana z użyciem własnych skryptów parsujących stronę. Były to m.in.:
Obróbka i normalizacja danych
Część filmów pobranych w powyższy sposób wciąż posiadała braki w danych. Z punktu widzenia algorytmu obliczającego stopień przynależności braki danych były dużym utrudnieniem. W przypadku braku np. stopnia popularności bądź średniej oceny podobieństwo obliczane dla każdego filmu względem filmu z brakującymi danymi wynosiło 0. Dane do wszystkich filmów zostały więc uzupełnione korzystając z nieoficjalnego API serwisu IMDB – MyMovieApi.com.
Wyszukiwanie filmów odbywało się za pomocą skryptu updateDatabase.py, który korzystał z biblioteki IMDB. Posiadało ona jedynie dwie metody:
- SearchMovieById(movie_id) – metoda zwracająca dane filmu w formacie JSON. Film był wyszukiwany w oparciu o identyfikator z serwisu IMDB, który to został pobrany na samym początku z pomocą API TheMovieDB.org.
- SearchMovieByTitle(title) – metoda zwracająca dane filmu w formacie JSON. Film był wyszukiwany w oparciu o tytuł filmu z serwisu TheMovieDb.org
Algorytm uzupełniający dane filmu korzystał w większości przypadków z pierwszej metody, która była zdecydowanie dokładniejsza. W przypadku braku identyfikatora filmu używana była metoda druga. W pliku uzupełniającym dane filmów prócz metody głównej main() zostały zaimplementowane następujące metody:
- addKeywords(cur, Keywords, id_movie) – metoda dodająca słowa kluczowe filmu do tabel: Keywords oraz FK_Keywords_Filmy;
- addLanguages(cur, languages, id_movie) – metoda dodająca słowa języki filmu do tabel: Jezyki oraz FK_Jezyki_Filmy;
- addGenres(cur, genres, id_movie) – metoda dodająca gatunki filmów przypisane do danego filmu, do tabel: Gatunki, FK_Gatunki_Filmy;
- addActors(cur, actors, id_movie) – metoda, która dodawała brakujących aktorów do danego filmu. Dane były dodawane do tabel: Aktorzy, FK_Aktorzy_Filmy;
- addCountries(cur, countries, id_movie) – metoda dodająca kraje produkcji danego filmu. Dane były zapisywane do tabel: Panstwa, FK_Panstwa_Filmy;
- addDirector(cur, directorName, id_movie) – metoda dodawała nazwę reżysera danego filmu. Nazwa była dodawana do tabeli: Następnie nadpisywano wartość klucza id_rezyser w tabeli Filmy.
W powyższych metodach pierwszym parametrem cur jest kursor bazy danych, drugim parametrem była lista atrybutów do zapisania, trzeci parametr to identyfikator filmu w bazie danych. Dodatkowo skrypt updateDatabase.py wykorzystywał metodę updateMovie(cur, rating, runtime, ratingCount, rated, id_movie). Metoda ta uzupełniała dane filmu: ocenę, czas trwania, liczbę ocen, ograniczenia wiekowe.
Większość informacji o filmach została pobrana z serwisu TheMovieDb ze względu na otwarte API, natomiast brakujące dane zostały uzupełnione danymi serwisu IMDB, gdyż jest on serwisem posiadającym największą bazę filmów na świeci. Liczba osób oceniających filmy często sięga kilkuset tysięcy.
Na potrzeby silnika rekomendacji filmów, baza danych została wypełniona danymi:
- 2727 filmów;
- 15986 aktorów;
- 6563 słów kluczowych;
- 1633 reżyserów;
- 108 języków;
- 92 państw;
- 24 gatunków.
Różne serwisy mają różną skalę oceniania filmów dlatego w celu ujednolicenia, wszystkie oceny użytkowników skalowane do wartości 1 do 5.
Średnia ocena filmu jest to średnia arytmetyczna ocen filmu. Przed przystąpieniem do wyznaczania rekomendacji, w celu uniknięcia problemu tzw. zimnego startu, początkową oceną filmu była ocena obliczona z wartości oceny danego filmu z trzech serwisów: TheMovieDB.org, IMDB i Filmweb.
Przygotowanie algorytmów
Najważniejszym elementem systemu rekomendacyjnego, będącym jego „sercem”, od którego zależy dokładność rekomendacji jest algorytm rekomendacji. Algorytm ten w niniejszym systemie bazuje na wspomnianym na początku podejściu do grupowania danych: Content Base Filtering, okraszonym odrobiną Collaborative filtering.
Content Base Filtering bazuje na analizie związków pomiędzy poszczególnymi filmami. Zgodnie z ideą tego typu filtrowania, jeśli użytkownik polubił dany film to spośród zbioru wszystkich filmów rekomenduje się te filmy, które charakteryzują się największym stopniem podobieństwa z filmem lubianym.
Na wstępie pisałem o „ludzkim obliczu” algorytmu. Nie zastosowałem jednak Collaborative filtering, czyli grupowania w oparciu o oceny użytkowników podobnych do nas, a posłużyłem się ocenami i popularnością filmów w różnych serwisach. Stopniem popularności, bo o nim mowa jest wartość bazująca na współczynniku uzyskanym z wartości popularności filmu, liczby ocen z serwisu IMDB, oraz liczby ocen z serwisu Filmweb. Wszak im bardziej popularny i wyżej oceniany film, tym większe prawdopodobieństwo że może się on okazać interesujący.
Kiedy możemy uznać, że użytkownik lubi dany film?
W celu ujednolicenia skali ocen, do zbioru filmów lubianych przez użytkownika zaliczają się wszystkie ocenione przez danego użytkownika filmy, których ocena spełnia warunek:[mathjax]

gdzie:
– jest to funkcja przynależności j-tego filmu do zbioru filmów lubianych danego użytkownika;
- o – jest to ocena j-tego filmu;
- min – jest to minimalna ocena w danej skali;
- max – jest to maksymalna ocena w danej skali.
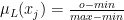
Zgodnie z powyższym, biorąc pod uwagę przyjętą skalę 1-5, do zbioru filmów lubianych przez użytkownika zaliczymy wszystkie filmy które zostały przez niego ocenione na co najmniej 4.
Filtrowanie atrybutów filmu
Pewnie nasuwa Ci się na myśl pytanie: no dobra, a co w przypadku, gdy dany film był opisany za pomocą różnych atrybutów tego samego typu, np. kilka gatunków, lub krajów produkcji?
Odpowiedź jest prosta: jest to przeliczane za pomocą wzoru zaczerpniętego z teorii zbiorów rozmytych. Dane pobierane z serwisu IMDB były danymi uporządkowanymi. Dla przykładu, gdy gatunek filmu opisany: komedia, dramat, oznaczało, że głównym gatunkiem jest komedia natomiast dramat jest gatunkiem drugorzędnym. W podobny sposób były uporządkowane pozostałe dane: kraje produkcji, aktorzy, języki, słowa kluczowe. W każdym przypadku były one przedstawione hierarchicznie od najistotniejszych. Taki sposób prezentacji danych umożliwił uzupełninie tabel o dodatkowy atrybut – DoM, który został użyty w algorytmie rekomendacji. Atrybutem ten użyty był we wszystkich tabelach, w których występowało hierarchiczne uporządkowanie kolejnym wartości. DoM jest to stopień przynależności (ang. Degree of Membership) znanym z teorii zbiorów rozmytych. Określał on przynależność danego elementu do zbioru rozmytego. Wartość DoM dla kolejnych wartości opisujących dany film (np. gatunek: komedia, dramat) była wyliczana ze wzoru:
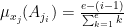
gdzie:
– jest to j-ty film z listy filmów;
– jest to i-ty element j-tej listy atrybutów danego filmu np. komedia;
- e – jest to liczba atrybutów listy
;
- i – jest to numer atrybutu listy

Przykładowo gatunek klasycznego filmu: „Chłopcy z ferajny” opisany jest za pomocą listy gatunków:
lista = [biograficzny, kryminalny, dramat]. Wartości funkcji przynależności wyglądają następująco:
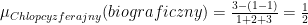
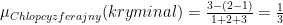

Zgodnie z powyższym gatunek biograficzny należy do zbioru rozmytego filmu „Chłopcy z ferajny” z wartością funkcji przynależności 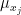
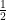
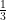
Stopień podobieństwa pomiędzy filmami
Do obliczenia współczynnika wsparcia rekomendacji danego filmu konieczne jest uprzedni obliczenie wartości stopnia podobieństwa między poszczególnymi filmami. Istnieje wiele metod obliczania stopnia podobieństwa. Do najpopularniejszych i najskuteczniejszych zaliczane są:
- Fuzzy Set Theoretic;
- Fuzzy Theoretic Cosine.
Pierwsza metoda bazuje na założeniach teorii zbiorów rozmytych. Zgodnie z tą metodą stopień podobieństwa to wartość:

gdzie:
– jest to funkcja podobieństwa filmów:
;
- n – jest toliczba atrybutów opisujących daną kategorię;
– jest to funkcja przynależności m-tego atrybutu do n-tego filmu.
Druga metoda:
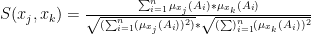
gdzie:
- n – jest to liczba atrybutów opisujących daną kategorię;
W swoim silniku rekomendacji opracowałem dwa algorytmy wykorzystujące obie metody. Zarówno pierwsza jak i druga metoda wykorzystuje ten sam schemat: dla dwóch filmów obliczana jest ważona suma podobieństwa kolejnych atrybutów wraz z ich wagami:
- Gatunki –
;
- Aktorzy –
;
- Języki –
;
- Państwa –
.
Wagi odzwierciedlają istotność atrybutów. Im wyższa waga tym większy wpływ atrybutu na ocenę użytkownika. Pełna wartość stopnia podobieństwa pomiędzy filmami obliczana jest za pomocą następującego wzoru:

gdzie:
– jest metodą obliczania stopnia podobieństwa: Fuzzy Throretic Cosine lub Fuzzy Set Theoretic.
Dla wszystkich filmów zawartych w bazie danych został obliczony stopień podobieństwa z pozostałymi filmami. Dane te są zawarte w bazie danych w tabeli FK_Filmy_Filmy. Kolumna Similarity zawiera stopnie podobieństwa obliczone metodą Fuzzy Theoretic Cosine, natomiast kolumna FuzzySimilarity zawiera stopnie podobieństwa obliczone metodą Fuzzy Set Theoretic. Żadna z powyższych metod nie uwzględnia ocen użytkowników ani stopni popularności, więc są on metodami zaliczanymi do grupy Content Based Filtering.
Współczynnik wsparcia rekomendacji
Współczynnik wsparcia rekomendacji jest wartością, która mówi o tym, w jakim stopniu dany film trafia w gust użytkownika. W niniejszym projekcie wartość ta jest obliczana za pomocą technik zaczerpniętych z teorii zbiorów rozmytych przy użyciu elementów społecznościowych, czyli liczby i wartości ocen, oraz współczynnika popularności.
Istnieje wiele podejść do obliczania wartości współczynnika rekomendacji. Opisywany system wykorzystuje metodę ważonych sum ocen(ang. Weighted-Sum Recommendation Method). Zgodnie z tą metodą dla każdego filmu należącego do zbioru filmów nieocenionych przez użytkownika obliczana jest ważona suma iloczynów:
- stopnia przynależności filmu już ocenionego do zbioru filmów lubianych,
- stopnia podobieństwa pomiędzy filmem lubianym a filmem nieocenionym.

gdzie:
- N – jest to zbiór wszystkich filmów, których dany użytkownik nie ocenił;
– jest to funkcja wsparcia rekomendacji;
- L – jest to zbiór wszystkich filmów lubianych przez użytkownika. Kryteria które musi spełnić film by znaleźć się w tym zbiorze opisałem w podpunkcie „Kiedy możemy uznać że użytkownik lubi dany film?”;
– jest to stopień przynależności filmu do zbiory filmów lubianych.
Jako najtrafniejsze rekomendacje zostają zwrócone użytkownikowi filmy, których współczynnik wsparcia rekomendacji ma największą wartość.
Wyznaczenie stopnia podobieństwa pomiędzy filmami
Cała logika silnika rekomendacji została przeniesiona na silnik bazy danych. Był to jeden z wielu etapów optymalizacji działania silnika rekomendacji, dlatego główne funkcje są funkcjami napisanymi w języku SQL.
Stopień podobieństwa jest wartością będącą sumą współczynników podobieństwa dla danych atrybutów filmów: gatunków, aktorów, języków, państw. Ich wartość była wyznaczana za pomocą zapytania SQL:
Fuzzy Theoretic Cosine
SELECT round(Num.Numerator/Den.Denominator, 7) AS genresSimilarity FROM (SELECT sum(tmp1.DoMMultiplication) AS Numerator FROM (SELECT g1.nazwa_gatunek AS gat1, g2.nazwa_gatunek AS gat2, g1.DoM AS DoM1, g2.DoM AS DoM2, CASE WHEN g1.nazwa_gatunek = g2.nazwa_gatunek THEN round(g1.DoM * g2.DoM, 5) WHEN g1.nazwa_gatunek != g2.nazwa_gatunek THEN 0 END AS 'DoMMultiplication' FROM (SELECT nazwa_gatunek, DoM FROM Gatunki AS g INNER JOIN FK_Gatunki_Filmy AS fk ON fk.id_gatunek = g.id_gatunek INNER JOIN Filmy AS f ON f.id_film = fk.id_film WHERE f.id_film = 1161) AS g1 JOIN (SELECT nazwa_gatunek, DoM FROM Gatunki AS g INNER JOIN FK_Gatunki_Filmy AS fk ON fk.id_gatunek = g.id_gatunek INNER JOIN Filmy AS f ON f.id_film = fk.id_film WHERE f.id_film = 1126) AS g2) AS tmp1) AS Num JOIN (SELECT m1.value*m2.value AS Denominator FROM (SELECT sqrt(sum(Pow(DoM, 2))) AS value FROM Gatunki AS g INNER JOIN FK_Gatunki_Filmy AS fk ON fk.id_gatunek = g.id_gatunek INNER JOIN Filmy AS f ON f.id_film = fk.id_film WHERE f.id_film = 1161) AS m1 JOIN (SELECT sqrt(sum(Pow(DoM, 2))) AS value FROM Gatunki AS g INNER JOIN FK_Gatunki_Filmy AS fk ON fk.id_gatunek = g.id_gatunek INNER JOIN Filmy AS f ON f.id_film = fk.id_film WHERE f.id_film = 1126) AS m2) AS Den;
Powyższy fragment kodu zwraca wartość stopnia podobieństwa dla metody Fuzzy Theoretic Cosine bazując jedynie na gatunkach filmów „Ojciec Chrzestny” i „Chłopcy z Ferajny” o identyfikatorach: 1126 i 1161. Wartość zwracanego parametru jest liczbą z przedziału [0,1] i dla powyższego przykładu wynosi 0,6532041.
Fuzzy Set Theoretic
SELECT sum(minimum)/sum(maksimum) AS genresSimilarity FROM (SELECT CASE WHEN g1.DoM IS NULL THEN least(0, g2.DoM) WHEN g2.DoM IS NULL THEN least(g1.DoM, 0) ELSE LEAST(g1.DoM, g2.DoM) END AS minimum, CASE WHEN g1.DoM IS NULL THEN greatest(0, g2.DoM) WHEN g2.DoM IS NULL THEN greatest(g1.DoM, 0) ELSE greatest(g1.DoM, g2.DoM) END AS maksimum FROM (SELECT fk.id_gatunek, DoM FROM Gatunki AS g INNER JOIN FK_Gatunki_Filmy AS fk ON fk.id_gatunek = g.id_gatunek INNER JOIN Filmy AS f ON f.id_film = fk.id_film WHERE f.id_film = 1161) AS g1 LEFT JOIN (SELECT nazwa_gatunek, fk.id_gatunek, DoM FROM Gatunki AS g INNER JOIN FK_Gatunki_Filmy AS fk ON fk.id_gatunek = g.id_gatunek INNER JOIN Filmy AS f ON f.id_film = fk.id_film WHERE f.id_film = 1126) AS g2 ON g2.id_gatunek = g1.id_gatunek UNION SELECT CASE WHEN g1.DoM IS NULL THEN least(0, g2.DoM) WHEN g2.DoM IS NULL THEN least(g1.DoM, 0) ELSE LEAST(g1.DoM, g2.DoM) END AS minimum, CASE WHEN g1.DoM IS NULL THEN greatest(0, g2.DoM) WHEN g2.DoM IS NULL THEN greatest(g1.DoM, 0) ELSE greatest(g1.DoM, g2.DoM) END AS maksimum FROM (SELECT fk.id_gatunek, DoM FROM Gatunki AS g INNER JOIN FK_Gatunki_Filmy AS fk ON fk.id_gatunek = g.id_gatunek INNER JOIN Filmy AS f ON f.id_film = fk.id_film WHERE f.id_film = 1161) AS g1 RIGHT JOIN (SELECT nazwa_gatunek, fk.id_gatunek, DoM FROM Gatunki AS g INNER JOIN FK_Gatunki_Filmy AS fk ON fk.id_gatunek = g.id_gatunek INNER JOIN Filmy AS f ON f.id_film = fk.id_film WHERE f.id_film = 1126) AS g2 ON g2.id_gatunek = g1.id_gatunek) AS maks_min
Powyższy fragment kodu zwraca wartość stopnia podobieństwa dla metody Fuzzy Set Theoretic, bazując jedynie na gatunkach filmów „Ojciec Chrzestny” i „Chłopcy z Ferajny” o identyfikatorach: 1126 i 1161. Wartość zwracanego parametru jest liczbą z przedziału [0,1] i dla powyższego przykładu wynosi 0,3333333. Podobne działanie musiałem przeprowadzić dla pozostałych atrybutów: aktorów, języka, krajów produkcji. Ze względu na objętość kodu wyznaczającego podobieństwo pomiędzy filmami fragmenty skryptu z powyższych przykładów zostaną zastąpione skrótami: genresSimilarity. Podobieństwa pozostałych atrybutów zostaną oznaczone analogicznie: actorsSimilarity, languagesSimilarity, countriesSimilarity.
SELECT round(((genresSimilarity.tmpSimilarity*6/10)+(actorsSimilarity.tmpSimilar ity*2/10)+(languagesSimilarity.tmpSimilarity*1/10)+(countriesSimilarity.t mpSimilarity*1/10)),7) AS 'Similarity' FROM genresSimilarity JOIN actorsSimilarity JOIN languagesSimilarity JOIN countriesSimilarity;
Powyższy fragment kodu zwraca ważony stopień podobieństwa pomiędzy filmami. Wagi odpowiadają istotnościom atrybutów. Im większy wpływ atrybutu na podobieństwo, tym większa wartość wagi. Dla omawianego przykładu stopień podobieństwa pomiędzy filmami „Ojciec Chrzestny” i „Chłopcy z Ferajny” współczynnik podobieństwa wyniósł:
- 0,5875419 dla metody Fuzzy Theoretic Cosine
- 0,3714281 dla metody Fuzzy Set Theoretic
Wartość stopni podobieństwa jest dosyć wysoka, gdyż oba filmy należą do kina gangsterskiego. Dla porównania stopnie podobieństwa pomiędzy filmami: „Ojciec Chrzestny” i „Straszny Film 5” wynoszą:
- 0,1801785 dla metody Fuzzy Theoretic Cosine;
- 0,1333333 dla metody Fuzzy Set Theoretic.
W celu łatwiejszego korzystania obie funkcje zostały zapisane w silniku bazy danych, jako funkcje: CosineSimilarity i FuzzySetsSimilarity. Obie funkcje na wejściu przyjmowały dwie wartości będące identyfikatorami filmów, dla których stopień podobieństwa ma zostać wyznaczony.
DROP FUNCTION `FuzzySetsSimilarity`; CREATE DEFINER=`root`@`localhost` FUNCTION `FuzzySetsSimilarity`(`id1` INT, `id2` INT) RETURNS DECIMAL(12,7) DETERMINISTIC NO SQL SQL SECURITY DEFINER RETURN ( SELECT round(((genresSimilarity.genresSimilarity*6/10)+(actorsSimilarity.actorsS imilarity*2/10)+(languagesSimilarity.languagesSimilarity*1/10)+(countriesSimilarity.countriesSimilarity*1/10)),7) AS Similarity FROM genresSimilarity JOIN actorsSimilarity JOIN languagesSimilarity JOIN countriesSimilarity;
Powyższa kod posłużył do utworzenia funkcji obliczającej stopień podobieństwa filmów. Kolejną funkcją bardzo ważną w procesie wyznaczania rekomendacji jest funkcja określająca stopień przynależności filmu do zbioru filmów lubianych przez użytkownika. Bazowała ona na wystawionej ocenie.
CREATE DEFINER=` root`@`localhost` FUNCTION `DoMLiked`(`ocena` INT, `MIN` INT, `MAX` INT) RETURNS DOUBLE DETERMINISTIC NO SQL SQL SECURITY DEFINER RETURN (ocena-MIN)/(MAX-MIN)
Parametrami wejściowymi były: ocena, minimalna ocena w danej skali, maksymalna ocena w danej skali. Została ona utworzona w oparciu o wzór funkcji z podpunktu „Kiedy możemy uznać że użytkownik lubi dany film?”.
Wyznaczanie współczynnika wsparcia rekomendacji
Ostatnią funkcją niezbędną do wystawienia rekomendacji była funkcja wyznaczająca współczynnik wsparcia rekomendacji dla danego filmu, dla danego użytkownika. Dla metody Fuzzy Set Theoretic miała ona następującą postać:
CREATE DEFINER=`root`@`localhost` FUNCTION `FuzzySetsSumDoM` (`uzytkownikId` INT, `filmId` INT) RETURNS DECIMAL(10,7) DETERMINISTIC NO SQL SQL SECURITY DEFINER RETURN (SELECT round((sum(FuzzySimilarity*Ocena)/count(tmp.idFilm1)),7) FROM (SELECT f.id_film AS idFilm1, ff.id_film2 AS idFilm2, DoMLiked(uf.ocena) AS 'Ocena', ff.FuzzySimilarity FROM Filmy f INNER JOIN FK_Uzytkownicy_Filmy uf ON uf.id_film = f.id_film INNER JOIN Uzytkownicy u ON u.id_uzytkownik = uf.id_uzytkownik INNER JOIN FK_Filmy_Filmy ff ON ff.id_film = f.id_film WHERE u.id_uzytkownik = uzytkownikId AND ff.id_film2 = filmId GROUP BY f.id_film, ff.id_film2, ff.FuzzySimilarity HAVING Ocena > 0.5) AS tmp)
Parametrami wejściowymi są tu identyfikator użytkownika oraz identyfikator filmu. Wartością zwracaną przez funkcję jest średnia ważona suma iloczynów stopni podobieństwa filmu wejściowego z każdym filmem ze zbioru filmów lubianych (FuzzySimilarity) i wartości stopnia przynależności rozpatrywanego filmu należącego do zbioru filmów lubianych(Ocena).
Ostatnim krokiem jest obliczenie wartości stopnia rekomendacji dla wszystkich filmów, których użytkownik do tej pory nie ocenił.
SELECT id_film, tytul_pl, f.ocena, FuzzySetsSumDoM(1,id_film) FROM Filmy f WHERE id_film NOT IN (SELECT f.id_film FROM FK_Uzytkownicy_Filmy uf INNER JOIN Filmy f ON f.id_film = uf.id_film INNER JOIN Uzytkownicy u ON u.id_uzytkownik = uf.id_uzytkownik WHERE u.id_uzytkownik=1) GROUP BY id_film, tytul_pl ORDER BY FuzzySetsSumDoM(1,id_film) DESC, f.ocena DESC, f.popularnosc DESC LIMIT 0,20;
Powyższy zapytani zwraca dwadzieścia filmów do tej pory nieocenionych przez użytkownika o identyfikatorze równym 1, których współczynnik wsparcia rekomendacji jest największy. W procesie testowania algorytmu rekomendacji używana była również wersja algorytmu z ważoną średnią oceną użytkowników. Miała ona następującą postać:
SELECT id_film, tytul_pl, ((FuzzySetsSumDoM(1,id_film)*75/100)+(f.ocena/10*25/100)) as Prognoza FROM Filmy f WHERE id_film NOT IN (SELECT f.id_film FROM FK_Uzytkownicy_Filmy uf INNER JOIN Filmy f ON f.id_film = uf.id_film INNER JOIN Uzytkownicy u ON u.id_uzytkownik = uf.id_uzytkownik WHERE u.id_uzytkownik=1 AND uf.ocena != -1) GROUP BY id_film, tytul_pl ORDER BY Prognoza DESC, f.ocena DESC, f.popularnosc DESC LIMIT 0,20;
W powyższym przykładzie rekomendacje dla danego użytkownika w 75% bazowały na współczynniku wsparcia rekomendacji. Pozostałe 25% była to średnia ocena społeczności dla danego filmu.
Przedstawienie wyników i wniosków
Na koniec chciałbym się podzielić kilkoma wnioskami i przemyśleniami. Oceniają zbudowany model bazowałem tylko i wyłącznie na ocenach i rekomendacjach wyznaczonych dla mnie i kilku bliskich osób. Nie pobierałem ocen z żadnej bazy filmów dostępnej na Kaggle, etc. Co zrobiłem, to pobrałem listę 300 najwyżej ocenianych filmów na IMDB, Filmweb i TheMovieDB, a następnie wraz z trzema osobami oceniłem filmy w skali od 1 do 5. Każdy z oceniających miał za zadanie ocenić wszystkie filmy które znał. Następnie każdy zbiór podzieliłem na dane uczące (70%) i walidujące (30%).

Co ciekawe, procent filmów dobrze zarekomendowanych wahał się w zależności od osoby oceniającej od 73% do 86%. Można zatem powiedzieć że co najmniej 3 na 4 filmy trafiały w gust oceniającego. Oczywiście w celu uproszczenia działania mechanizmu, wszystkie filmy które zostały zarekomendowane przez silnik, a nie były obejrzane przez użytkownika zostawały automatycznie odrzucone i nie brane pod uwagę przy ocenianiu systemu.

W ramach ciekawostki, chciałbym również przedstawić jak wyglądał stopień podobieństwa pomiędzy filmami. Dla 20 najwyżej ocenianych filmów macierz podobieństw, wyznaczona za pomocą metody Fuzzy Theoretic Cosine wyglądała następująco:

Co ciekawe, dwa najbardziej do siebie podobne filmy w tym zestawieniu, to: „Dzisiejsze czasy”, oraz „Światła wielkiego miasta”. W tym przypadku wysokie podobieństwo jest uzasadnione. Nieme kino produkcji w reżyserii Charlesa Chaplina, produkcja w latach 30-tych ubiegłego wieku, to tylko niektóre podobieństwa rzucające się w oczy. Na drugim biegunie mamy filmy które różni niemal wszystko. Według algorytmu „Władca Pierścieni: Drużyna Pierścienia” i „Casablanca” to dwa najsłabiej ze sobą powiązane filmy. I faktycznie, różni je niemal wszystko: tematyka, gatunek, aktorzy, lata produkcji.
We wszystkich przypadkach, w których stopień podobieństwa przekracza 0.7, możemy mówić o dużym podobieństwie. Niektóre wyniki można łatwo uzasadnić, a inne wymagają bliższego przyjrzenia się atrybutom które je opisuję. Tak też jest w przypadku filmów „Podziemny krąg” i „Dwunastu gniewnych ludzi”, których stopień podobieństwa wynosi 0.79.
Podsumowując, największym problemem z jakim się borykałem podczas tego projektu były dane. Brak sprawdzonego API do pobierania informacji o filmach powodował duże problemy. Było całe mnóstwo braków, duplikatów i niespójności. Śmiało mogę powiedzieć że wyczyszczenie, deduplikacja i normalizacja danych zajęły mi 70% czasu trwania tego projektu. Wprawdzie dane filmów z IMDB są dostępne na Kaggle, ale skoro miał być Open Source’owy projekt zrobiony od zera, to nie mogłem się z tego wycofać 🙂
Sam silnik rekomendacji działał bardzo dobrze. Co bardzo mi się spodobało, pozwalał odkryć ciekawe klasyki, które giną w otchłaniach przepełnionych blockbusterami baz IMDB i Filmwebu. Implementacja metody zbiorów rozmytych okazała się nad wyraz przyjemna i w oparciu o odpowiednią literaturę (w razie potrzeby tytuły pozycji z których korzystałem mogę podesłać na e-mail) nie stanowiła dużego wyzwania.
Dosłownie kilka minut po zakończeniu testowania silnika, w chwili kiedy piszę te słowa widzę kilka słabych punktów systemu, które mógłbym poprawić. Z pewnością, gdybym kiedyś powrócił do tematu rekomendacji filmów, to postaram się nanieść odpowiednie poprawki. Jedną z nich mógłby być dodatkowy atrybut przechowujący dane scoringowe, dla danego filmu i użytkownika, którego to brak wpływał znacząco na wydajność.
Podsumowanie
Jeśli projekt wydał Ci się interesujący, bądź masz jakieś spostrzeżenia i uwagi, proszę podziel się nimi w komentarzu, lub skontaktuj się ze mną.
Wszystkie pliki utworzone przy projekcie można znaleźć na moim GitHub’ie.
Widzę, że post może nie najnowszy, ale dopiero trafiłem na bloga i czytam go sobie od początku. Jestem pod wrażeniem ilości pracy jaką w to włożyłeś. Ile czasu zajęło Ci opracowanie tego? Czy zanim doszedłeś do tego co jest tu zaprezentowane, próbowałeś jakiś innych sposobów?
Hej Adam! Dziękuję za miłe słowo i zachęcam do odwiedzania bloga 🙂
Co do czasu jaki poświęciłem na opracowanie tego projektu, to ciężko mi go estymować. Był on częścią większego projektu nad którym spędziłem wiele miesięcy.
Testowałem kilka metod wyznaczania rekomendacji opartych o filtrowanie „podobnych produktów”. Niestety nie jestem w stanie przedstawić teraz szczegółowych wyników gdyż było to dosyć dawno (wykonywałem eksperymenty na przełomie 2013 i 2014 roku), jednak gdybyś był bardzo ciekaw, to daj znać – spróbuję odgrzebać notatki i podzielę się swoimi wnioskami 🙂
Bardzo ciekawy post. Masz to może gdzieś na gicie?
Hej Pawko, dziękuję za miłe słowa. Niestety nie mam tego nigdzie udostępnionego. 🙁