
Zanim przejdę do praktycznego zastosowania logiki rozmytej w Machine Learning’u, bądź silnikach rekomendacyjnych, czuję się zobowiązany do popełnienia krótkiego, teoretycznego wstępu, tak by każdy z czytających mógł zapoznać się z główną ideą zbiorów rozmytych. Pierwszy projekt który opublikuje na blogu będzie pisany „od zera”. W realnym projekcie, nie korzystając z żadnych gotowych bibliotek, zaimplementuję ideę zbiorów rozmytych w połączeniu z jednym z podejść stosowanych w silnikach rekomendacyjnych (Content-based filtering). Wszak łatwiej implementować coś co się dogłębnie rozumie. A więc zaczynamy…
Opisane w jednym z poprzednich artykułów przykłady doskonale obrazują podstawowe różnice pomiędzy klasyczną logiką a logiką rozmytą. Główną różnicą jest więc „rozmycie” wprowadzone pomiędzy wartościami granicznymi: 0 i 1. Kuszącym wydaje się być stwierdzenie, iż wartości, które przyjmuje dany element w odniesieniu do zbioru są prawdopodobieństwami, z jakimi może on zostać do niego przypisany. Byłoby to jednak błędne stwierdzenie, gdyż prawdopodobieństwem określamy wartości zjawisk, co do których nie mamy całkowitej pewności a to przeczy idei zbiorów rozmytych dlatego powszechnie używa się pojęcia: stopień przynależności. Zgodnie ze stopniem przynależności będziemy w stanie stwierdzić, z jaką wartością dany obiekt przynależy do danego zbioru. Wyznaczenie stopnia przynależności możliwe jest dzięki funkcji przynależności. Może ona przyjmować różne kształty w zależności od badanego zjawiska, obiektu czy też sytuacji decyzyjnej.
Logikę rozmytą wykorzystuje się w wielu dziedzinach życia. Używamy jej codziennie w fabrykach, samochodach, systemach informatycznych. Szczególnym przypadkiem wykorzystania logiki rozmytej są systemy rozmyte. Systemem rozmytym nazywać będziemy system oparty na logice rozmytej składający się z trzech bloków: fuzyfikacji, wnioskowania i defuzyfikacji.
Większość systemów rozmytych opartych na logice rozmytej wykorzystuje tzw. zmienne lingwistyczne będące określeniami zaczerpniętymi z języka potocznego. To dzięki nim możliwe jest przedstawienie wartości uzyskanych w procesie fuzyfikacji i wnioskowania w języku naturalnym, zrozumiałym dla ludzi.
Reprezentacja zbioru rozmytego
Formalnie zbiór rozmyty Z określony w pewnej przestrzeni X to zbiór:[mathjax]
\[Z=\left\{\left(x,\mu{}\left(x\right)\right)\ :x\in{}X\right\},\]
gdzie: ![\mu:X\rightarrow[0,1]](https://s0.wp.com/latex.php?latex=%5Cmu%3AX%5Crightarrow%5B0%2C1%5D&bg=ffffff&fg=000&s=0&c=20201002)
Zgodnie z założeniami teorii zbiorów rozmytych wartość funkcji 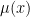
Każdy element zbioru rozmytego można zatem przedstawić w postaci dwójki uporządkowanej 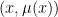
Powszechnie stosuje się dwa sposoby reprezentowania zbiorów rozmytych:
\[Z=\left\{\left(x_{1},\mu_{z}\left(x_{1}\right)\right),\left(x_{2},\mu_{z}\left(x_{2}\right)\right),…,\left(x_{n},\mu_{z}\left(x_{n}\right)\right)\right\}\]
\[Z=\left\{\left(\mu_{z}\left(x_{1}\right)/x_{1}\right),\left(\mu_{z}\left(x_{2}\right)/x_{2}\right),…,\left(\mu_{z}\left(x_{n}\right)/x_{n}\right)\right\}\]
Funkcja przynależności
Funkcją przynależności nazywamy funkcję, według której obliczany jest stopień przynależności badanego elementu do danego zbioru. Może ona przyjmować różne postaci, m.in. liniową, trapezoidalną, trójkątną, kwadratową.
Funkcję przynależności będziemy przedstawiać w układzie współrzędnych, na którym to oś rzędnych reprezentuje stopień przynależności do danego zbioru, natomiast oś odciętych to wartości charakterystyczne dla badanego obiektu, czy też zjawiska np. wzrost, okres czasu, siła.
Wynikiem działania funkcji przynależności jest stopień przynależności 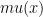
Wygląd wykresu funkcji przynależności jest różny w zależności od rozpatrywanego problemu i właściwości badanego elementu. Dla przykładu chcąc określić czy dana osoba jest wysoka należy napisać funkcję przynależności osób do zbioru osób wysokich. Podstawowymi danymi, które są do tego potrzebne są: wzrost osoby bezwzględnie wysokiej, wzrost osoby bezwzględnie niskiej oraz wzrost osoby rozpatrywanej. Pierwsze dwie zmienne służą, jako odniesienie do trzeciej zmiennej. W realnych sytuacjach do wyznaczenia wartości dwóch pierwszych zmiennych zazwyczaj potrzebna jest wiedza eksperta. Funkcja określająca przynależność osoby do zbioru osób wysokich (dla osób, których wzrost mieści się w przedziale [n, w]) wygląda następująco:
\[\mu(x)=\frac{(x-n)}{(w-n)}\]
gdzie:
x – wzrost osoby badanej
n – wzrost osoby niskiej
w – wzrost osoby wysokiej
Dla osoby o wzroście 175 cm wartość funkcji przynależności wynosi 0,5 przy założeniu, że wzrost osoby bezwzględnie wysokiej to 190 cm, a wzrost osoby bezwzględnie niskiej to 160 cm. Dla powyższych danych wykres funkcji przynależności wygląda następująco:

Operacje na zbiorach rozmytych
Dzięki zbiorom rozmytym i używanej w nich funkcji przynależności możliwe jest reprezentowanie nieprecyzyjnych stwierdzeń. Bez podstawowych operatorów stosowanych w teorii zbiorów stałyby się one jednak bezużyteczne ze względu na niemożność odwzorowywania wiedzy, dlatego też powszechnie stosuje się w nich tzw. operatory rozmyte będące uogólnieniem operatorów boolowskich z teorii zbiorów. Są to m.in. suma, iloczyn i dopełnienie.
Dla zbiorów rozmytych A, B zawartych w przestrzeni X iloczynem, lub przecięciem zbiorów (ang. intersection) nazywamy taki podzbiór rozmyty ∩ w przestrzeni X, że jego funkcja przynależności spełnia:
\[\mu_{A\cap B}(x)=min(\mu_{A}(x),\mu_{B}(x))\]
dla każdego x ∈ X.
Dla zbiorów rozmytych A, B zawartych w przestrzeni X sumą zbiorów (ang. union) nazywamy taki podzbiór rozmyty ∪ w przestrzeni X, że jego funkcja przynależności spełnia:
\[\mu_{A\cup B}(x)=max(\mu_{A}(x),\mu_{B}(x))\]
dla każdego x ∈ X.
Dla dowolnego zbioru rozmytego A zawartego w przestrzeni X dopełnieniem zbioru A nazywać będziemy taki zbiór Ac będący podzbiorem przestrzeni, że:
\[\mu_{A^{C}}(x)=1-\mu_{A}(x)\]
dla każdego x ∈ X.
Iloczynem kartezjańskim zbioru A ⊆ X i B ⊆ Y nazywamy taki zbiór rozmyty, że jego funkcja przynależności spełnia:
\[\mu_{AxB}(x,y)=min(\mu_{A}(x),\mu_{B}(x))\]
lub
\[\mu_{AxB}(x,y)=\mu_{A}(x)\mu_{B}(x)\]
dla każdego x ∈ X i y ∈ Y.